
Pathway E1
Embedding Strategy
Model comparison, dimensionality trade-offs and chunking policy design for your document corpus and multilingual requirements.
View embedding sprint →
Independent vector advisory · Vancouver, BC
Embedding strategy, RAG pipeline architecture and semantic search programmes for Canadian enterprises — documented assumptions, benchmarked on your corpus.
BN on file · 675 West Hastings Street · Pacific Time
“Knowledge systems deserve the same rigour as production ML pipelines — measured embedding quality, documented retrieval assumptions and a clear path from raw documents to grounded answers.” CogniVector · Vector Charter
Capability lattice
Each pathway maps to a distinct stage of your knowledge-system roadmap — from first embedding evaluation through enterprise RAG deployment.
Model comparison, dimensionality trade-offs and chunking policy design for your document corpus and multilingual requirements.
View embedding sprint →
Retrieval architecture, reranking layers, grounding policies and evaluation harnesses for production-grade answer generation.
Explore RAG blueprint →
Hybrid retrieval blueprints combining dense vectors, sparse lexical signals and metadata filters.
Launch plan →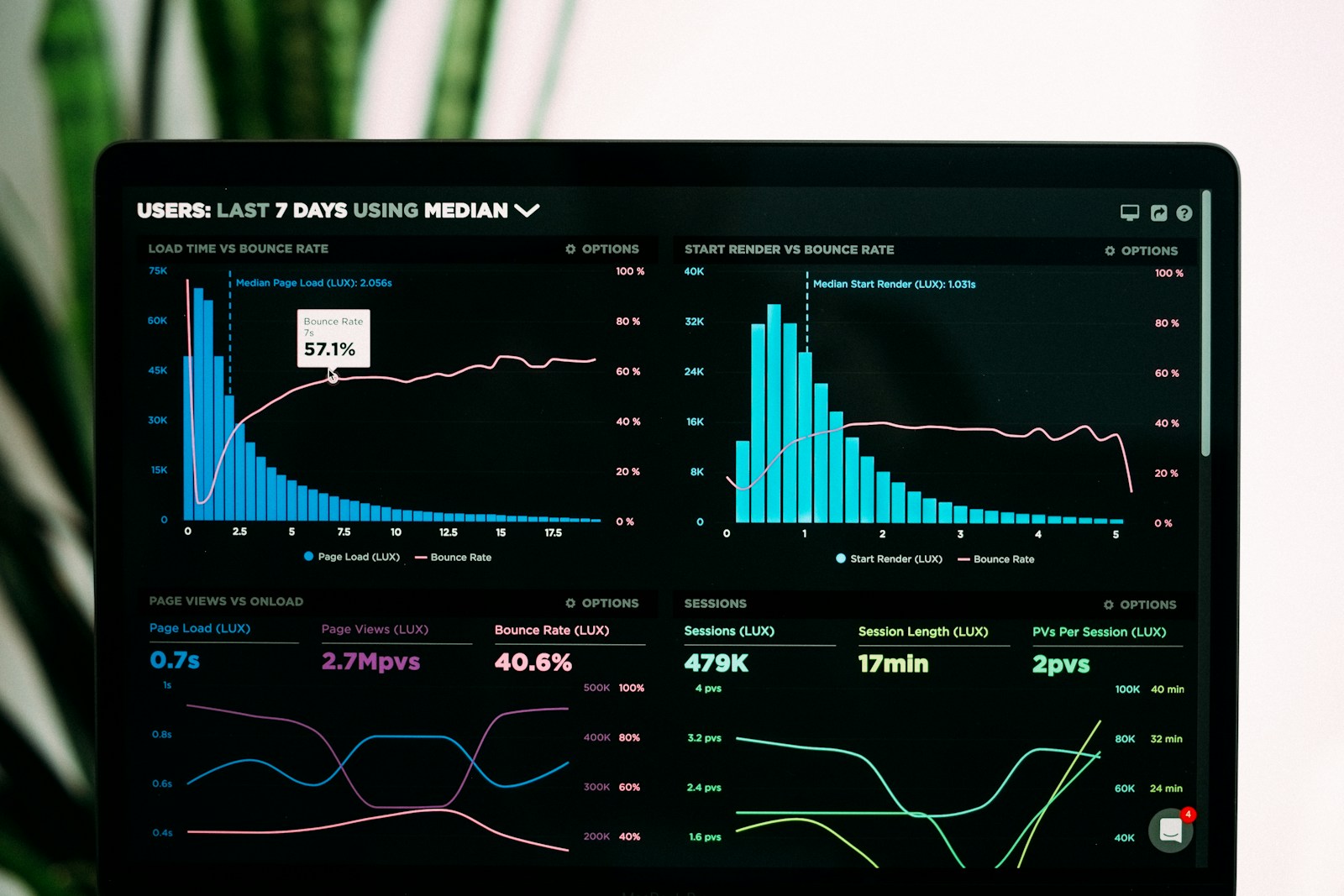
Entity linking, graph-augmented retrieval and structured context for regulated knowledge domains.
Graph integration →
We accept no referral fees from vector database or embedding API vendors. Recommendations follow your benchmark results — not our margin on a licence sale.
Advisory method
Each phase produces documented deliverables your engineering team can implement or hand to integration partners.
Document taxonomy, access controls and update cadence
Model shortlist with recall@k on held-out queries
Vector store selection, sharding and latency targets
Prompt templates, grounding rules and guardrails
Monitoring dashboards, reindex playbooks and drift alerts
Who we serve
Vancouver advisory for teams navigating embedding procurement, RAG launch and semantic search migration.
CogniVector helps product teams, data leaders and enterprise architects make defensible vector intelligence decisions. We translate vendor documentation into comparable metrics: chunking strategy, index latency, recall benchmarks and realistic infrastructure expenditure timelines.
From our studio at 675 West Hastings Street, we model retrieval performance using your document corpus, embedding dimension targets and query patterns. Whether you are evaluating a managed vector store or planning an on-premise semantic search deployment, we provide structured comparison frameworks grounded in Canadian privacy expectations and PIPEDA-aligned data handling.
Every engagement begins with a corpus audit — quantifying document types, metadata richness and access-control boundaries before recommending an embedding model family or chunking policy.

Track record
Programmes
Embedding benchmarks, RAG architecture diagrams or semantic search rollout plans — scoped to your corpus size and compliance requirements.
Two-week model comparison with chunking experiments and recall benchmarks on your sample corpus.
C$6,500–C$12,000

Full retrieval architecture with reranking design, evaluation harness and grounding policy documentation.
C$14,000–C$28,000

Hybrid search rollout plan with index sizing, query analytics framework and migration timeline.
C$9,800–C$19,500
Studio sessions


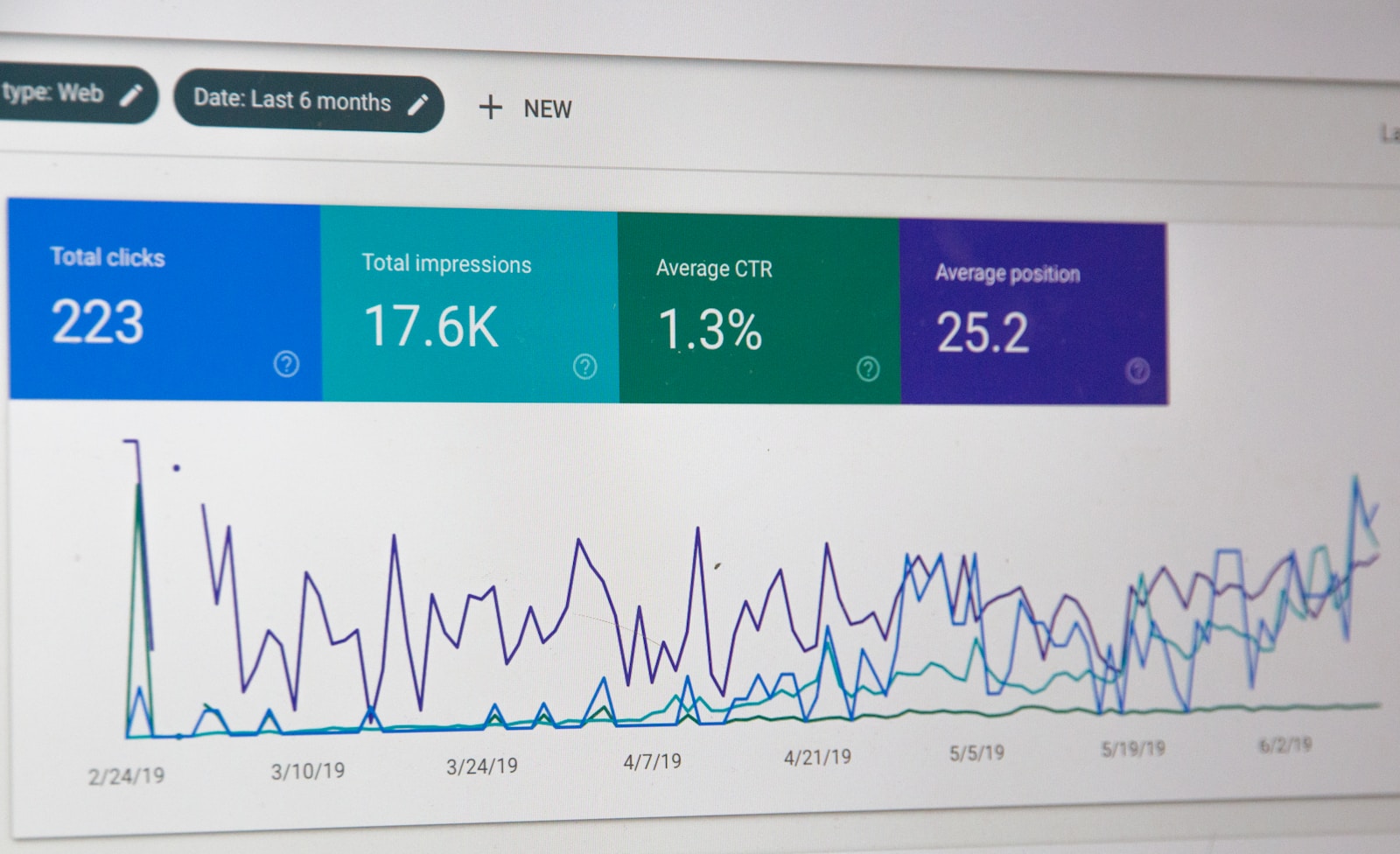
Common questions
No. CogniVector is an enterprise vector intelligence advisory studio — we design embedding strategies, RAG pipelines and semantic search architectures from our Vancouver studio. We do not sell consumer chatbot subscriptions, operate an app marketplace or broker personal data.
We benchmark open-weight and commercial embedding families against your corpus — measuring recall@k, latency and total cost of ownership. Recommendations depend on language mix, document length distribution and deployment constraints.
We establish held-out query sets with human-reviewed ground truth, then track retrieval precision, answer faithfulness and hallucination rates. Metrics are documented in an evaluation harness your team can rerun after model or index updates.
Our vector lab sits at 675 West Hastings Street, Suite 1400, Vancouver, BC — in the downtown financial district. We welcome scheduled visits for architecture reviews and embedding strategy workshops by appointment.
Start here
Book a vector audit or walk through our RAG readiness framework with your document corpus and infrastructure budget.
Book a vector audit
Our content covers enterprise vector intelligence advisory for informational purposes. Performance benchmarks and infrastructure estimates reflect illustrative assumptions — individual outcomes vary with corpus quality, query patterns and operating decisions.